

DeepSeek-R1 established reinforcement learning as the standard for training reasoning into LLMs, but the research since then has shifted. We aren’t seeing a blind rush to scale anymore; we are seeing a coordinated effort to figure out what the initial approach got wrong. The ~30 papers that mattered this week don’t just offer incremental gains. They suggest that the current training, memory, and inference pipelines have structural flaws that need fixing before we can push further.
The Debugging Phase of RL
The industry’s aggressive pivot to reinforcement learning with verifiable rewards (RLVR) was initially treated as a pure scaling play, but that assumption is cracking. We are finding that standard RL doesn’t necessarily create new reasoning capabilities; often, it just uncovers what was already there. MRPO provides the strongest evidence for this, identifying a “bias manifold” that traps the model’s exploration. Their work suggests that unless we force the policy into orthogonal directions, we aren’t actually expanding the model’s intelligence, just its compliance.
This rigidity in the pipeline is what ReMiT tries to break. By feeding RL insights backward into pretraining, essentially using the tuned model to reweight the learning of the base model, they argue that the strict separation between “learning to speak” (pretraining) and “learning to think” (post-training) is artificial and inefficient.
When we look at the actual mechanics of training, two distinct problems emerge. The first is training stability. DISPO addresses this by splitting gradient updates into four regimes based on whether the model was confident and whether it was correct. When the model is confident and right, it unclips the upper bound to reinforce aggressively. When the model is confident and wrong, the danger zone for catastrophic collapse, it clamps down hard. This gets 61.04% on AIME’24 with Qwen3-14B versus 50.21% for DAPO, with gains holding across 8B dense to 30B MoE. ARM tackles a related but different failure: the mode collapse that plagues GRPO, where the model converges on a narrow set of reasoning patterns and ignores valid alternatives. ARM reweights advantages based on prompt perplexity and answer confidence, redistributing probability mass toward underexplored but correct chains.
The second problem is reward quality. Sparse pass/fail signals don’t tell the model where its reasoning went wrong. Grad2Reward solves this by running a single backward pass through an LLM-as-Judge to extract token-level process rewards via gradient attribution, turning a binary verdict into a dense map of which tokens contributed to success or failure. TrajFusion takes a more behavioral approach: instead of improving the reward signal, it restructures the training data itself, interleaving incorrect trajectories with reflection prompts and correct trajectories to create fused samples that explicitly model trial-and-error. Sample length adapts to problem difficulty, providing richer supervision where errors are most informative.
Perhaps most encouragingly for smaller teams, CPMöbius managed to achieve competitive math performance (+4.9 average accuracy on Qwen2.5-Math-7B) using a Coach-Player setup without any external data. The Coach generates increasingly targeted problems, rewarded based on the Player’s improvement. If this generalizes, it removes one of the last bottlenecks keeping smaller labs from training competitive reasoning models.
Memory as an Active Process
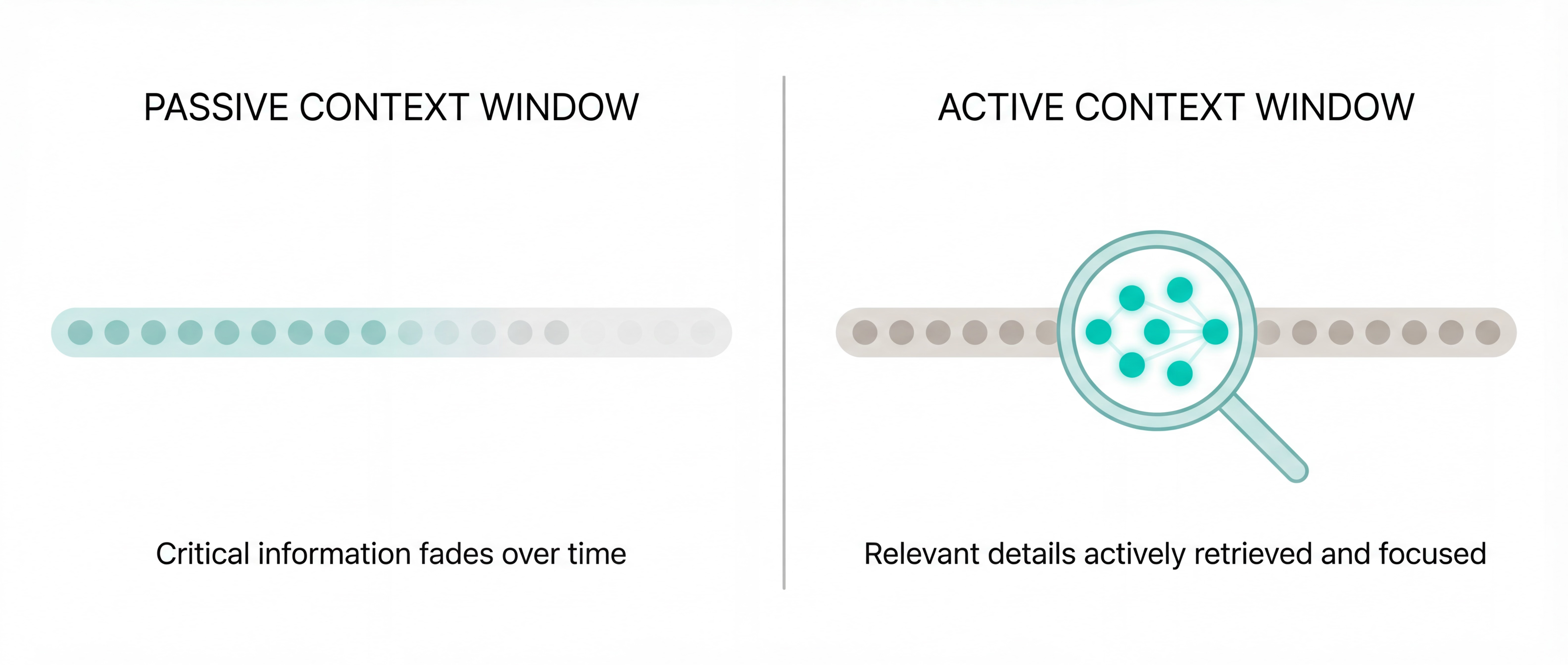
Better training only works if the model can hold onto the right information. There is a growing consensus that passive context windows, even massive ones, are failing at multi-hop reasoning because they don’t distinguish between “seeing” data and “remembering” it. InfMem demonstrates this clearly: passive updates during streaming consistently let low-salience bridging evidence slip away, exactly the kind of information multi-hop reasoning depends on. Their fix is a “PreThink-Retrieve-Write” protocol where the model actively monitors whether it has enough evidence before generating an answer. If it doesn’t, it triggers targeted retrieval from the document and compresses what it finds into a bounded memory buffer. If it does, it stops early. That early stopping alone cuts inference latency by nearly 4x, and the protocol adds +10.17 accuracy points on Qwen3-1.7B across benchmarks from 32K to 1M tokens. The key shift is that memory becomes a managed resource with an explicit sufficiency check, not a passive window the model hopes contains what it needs.
This shift toward active memory management is showing up at the hardware level too. ROSA-Tuning offloads the retrieval step to the CPU using a suffix automaton, an old but fast data structure for exact string matching, that locates relevant historical positions and feeds only those to the GPU through an asynchronous pipeline. The GPU never wastes cycles searching; it only reasons over what the CPU already identified as relevant. This substantially restores long-context performance for windowed-attention models while preserving their efficiency advantage.
At the attention mechanism level, OVQ Attention addresses a core weakness of linear attention alternatives: they accumulate state in ways that overwrite earlier information, causing what amounts to in-context catastrophic forgetting. OVQ replaces this with an associative memory based on online clustering, where updates are sparse and key-targeted rather than global. The result is a sequence mixing layer with linear compute and constant memory that retains earlier context. Testing is limited to sub-500M parameters, but the mechanism avoids the fundamental failure mode that has kept linear attention from being practical. Momentum Attention tackles the same problem from a different angle, using symplectic augmentation to embed velocity information into queries and keys. The practical consequence is that it enables single-layer induction head formation, bypassing a known constraint that normally requires at least two layers of attention.
The most surprising result in this section is Monotonicity as an Architectural Bias. The idea is simple: enforce monotonicity selectively in feed-forward sublayers while leaving attention unconstrained. The effect is that attention continues to handle negation, contradiction, and complex semantic relationships, while the feed-forward layers are forced to provide order-preserving refinement. This drops adversarial attack success from roughly 69% to 19% with only marginal degradation in summarization quality. A 50-point reduction from a single architectural constraint that requires no retraining of existing attention weights is a result that deserves more scrutiny than it will likely receive in an RL-dominated week.
Inference is no Longer Just Compression
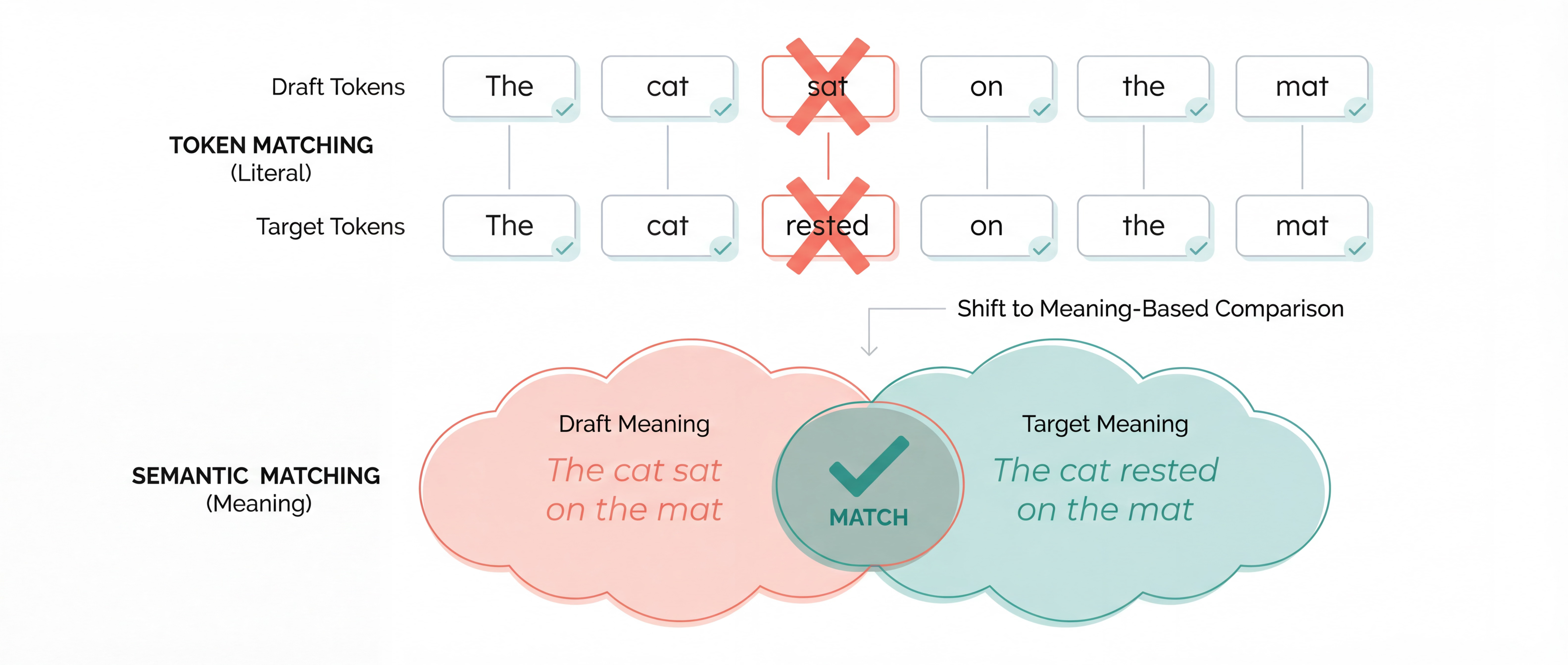
Once these models are trained and architected, running them efficiently has become a reasoning problem in itself. We are moving past simple quantization (making the model smaller) toward semantic optimization (making the model smarter about how it generates). SemanticSpec is the standout here. Standard speculative decoding wastes time rejecting drafted tokens that are technically different from what the target model would produce, even when the draft conveys the same meaning. SemanticSpec probes the target model’s hidden states to estimate semantic-level generation probabilities, then verifies at that granularity instead of token-by-token. This yields 2.7x speedup on DeepSeekR1-32B, with the gains scaling as reasoning chains get longer, precisely the regime where token-level verification is most wasteful.
Even where we do see traditional compression, it’s getting structurally smarter. BPDQ makes 2-bit quantization, usually a death sentence for reasoning, viable on consumer hardware. Instead of forcing weights through a fixed uniform grid, it constructs variable quantization grids using bit-planes and scalar coefficients, refined iteratively with second-order information. The result: Qwen2.5-72B running on a single RTX 3090 at 2-bit with 83.85% GSM8K accuracy, where standard 2-bit methods on the same model produce essentially unusable output for reasoning tasks.
On the serving side, R2-Router reframes model routing by jointly selecting the LLM and an output length budget. A powerful model with constrained output can outperform a weaker model given unlimited tokens at comparable cost, a configuration invisible to prior routers that only consider model selection. The reported 4-5x cost reduction is a production-relevant number. LycheeDecode targets the KV cache bottleneck directly, partitioning attention heads into a small retrieval set that dynamically finds crucial tokens and a sparse majority that reuses those selections, maintaining LongBench performance while cutting cache cost.
The tension to watch is that many of these fixes assume the current GRPO optimization style is here to stay. If the underlying optimization method changes next month, half of these training papers become obsolete. The architectural and inference changes, however, solve deeper structural issues. They will likely remain relevant regardless of how the training recipe evolves.
